[TOC]
云计算
要考试了来复习了呀;来一下重点总结
1. 云计算定义,与大数据关系,三层服务
2. google云平台的,包含的那些组件技术;gfs的技术,与关系型数据库的差别;mapReduce的思想
3. 亚马逊组件架构,s3的技术特点
4. 微软的云平台的数据库和其他的区别
5. hadoop工作模式,主要架构,起源,HDFS内部特性;
6.
7. 虚拟化产品,服务器虚拟化用的技术;虚拟机隔离,及转移
8. openstack的组件和nova等技术
9. 网络拓扑算法
云计算概论
数据时代的特点:密度价值底,数据量大,快速,多样;复杂度 4V+1C
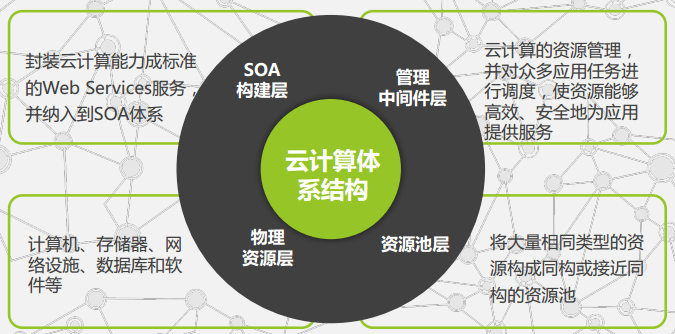
云计算与大数据的关系: G(我们的目标)=F(与计算)(X):大数据
- Saas(软件即服务)
- Paas(平台即服务)
- Iaas(基础即服务)
google云技术解析
文件系统GFS
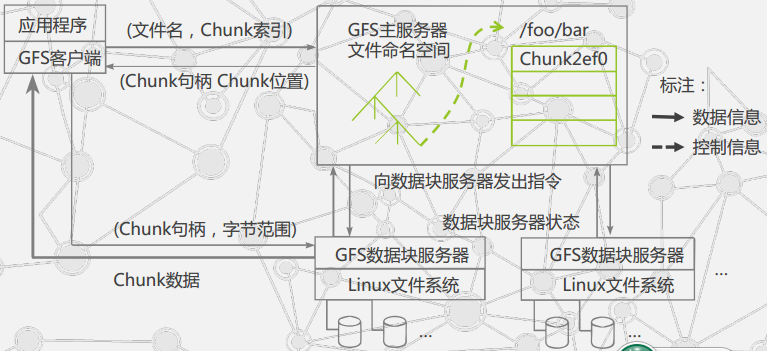
系统节点分为三种
- CLient(客户端):是GFS提供给应用程序的访问接口,以文库文件的形式提供
- Master(主服务器):是GFS的管理节点,负责整个文件系统的管理
- Chunk Server:负责具体的存储工作
具体的实现机制:客户端首先访问Master节点,获取交互的Chunk Server信息,然后访问这些Chunk Server,完成数据的存取工作,实现了控制流和数据流的分离.Clint与master之间只用 控制流,无数据流,极大的降低了Mseter的处理,Client与Chunk server之间传输数据流,同时由于文件被分成对个chunk进行分布式存储,CLint可以访问多个Chunk server实现整个系统的I/O高度并行.提高性能
GFS特点
– 采用中心服务器模式:方便增加Chunk Server,不存在元数据的一致性问题,可以掌握所有的chunk setver的情况,方便进行负债均衡
– 不缓存数据:文件大多是流失读写,不存在大量重复读写,使用Cache对性能提升不大,使用擦车对本地数据一致性维护很复杂
– 用户态下实现,利用POSIX编程接口存取数据降低了实现难度,
Master容错机制: 命名空间(Name Space),整个文件的目录结构;Chunk与文件名的映射表;Chunk副本信息,每个Chunk默认有三个副本;当Mater发生故障时,可以恢复以上元数据,GFS还提供master的远程备份功能
Chunk server容错:使用副本方式;多存储副本(默认三个),对于每个chunk当所有副本全部写入成功才视为写入成功(数据一致性);CHunk默认大小为64M,每个文件被分为多个Chunk;以Block为单位进行划分,大小为64kb,每个block对应一个32bit的校验和
系统管理技术

MapReduce
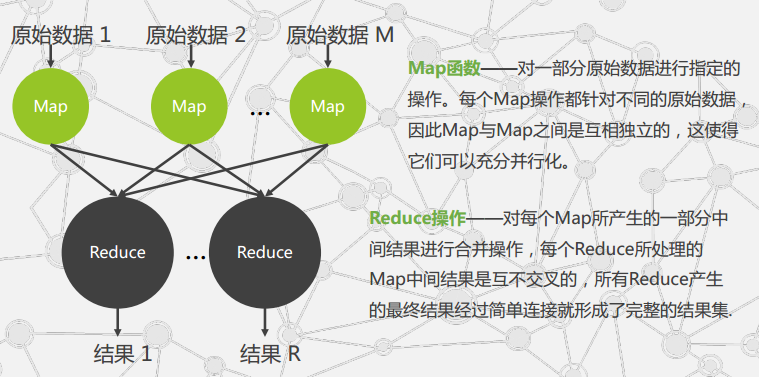
MapReduce并行编程思想最早在1995年提出,与传统的分布式程序相比,MapReduce封装了并行处理,容错处理,本地化计算,负载均衡等细节,还提供了一个简单而强大的接口;
MapReduce把对数据集的大规模操作,分发给一个主节点管理下的各分节点共同完成,通过这种方式实现任务的可靠执行与容错机制
实现机制:
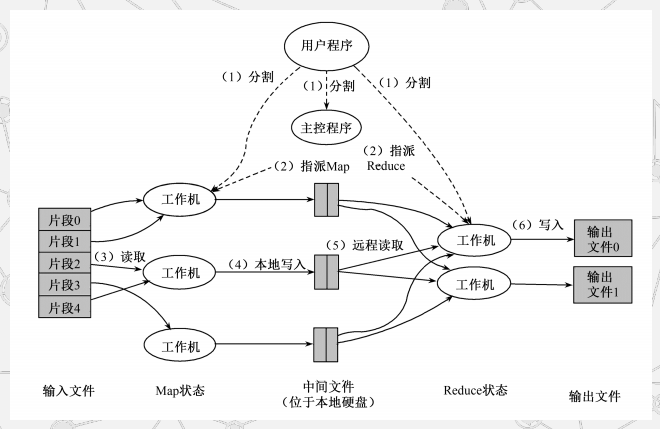
(1)MapReduce函数首先把输入文件分成M块
(2)分派的执行程序中有一个主控程序Master
(3)一个被分配了Map任务的Worker读取并处理相关的输入块
(4)这些缓冲到内存的中间结果将被定时写到本地硬盘,这些数据通过分
区函数分成R个区
(5)当Master通知执行Reduce的Worker关于中间<key,value>对的位置
时,它调用远程过程,从Map Worker的本地硬盘上读取缓冲的中间数据
(6)Reduce Worker根据每一个唯一中间key来遍历所有的排序后的中间
数据,并且把key和相关的中间结果值集合传递给用户定义的Reduce函数
(7)当所有的Map任务和Reduce任务都完成的时候,Master激活用户程序
容错机制:通过从新执行失效的地方来实现容错
master失效:master会周期性的设置检测点,并导出master的数据,一旦某个任务失效,系统从最近的一个监测点恢复并重新运行,整个程序是重新开始的,master毕竟只有一个
Worker失效:master会周期性给worker发送ping命令,如果没有应答,master就会认为worker失效了,会终止对这个worker的任务调度,把它的任务分配给其他人重新执行;
Chubby
Ch u b b y 是 Goog l e 设 计 的 提 供 粗 粒 度 锁 服 务 的 一 个 文 件 系 统 , 它 基 于 松 耦 合分 布 式 系 统 , 解 决 了 分 布 的 一 致 性 问 题
bigtable
Bigtable是一个分布式多维映射表,表中的数据通过一个行关键字(Row Key)、一个列关键字(Column Key)以及一个时间戳(Time Stamp)进行索引
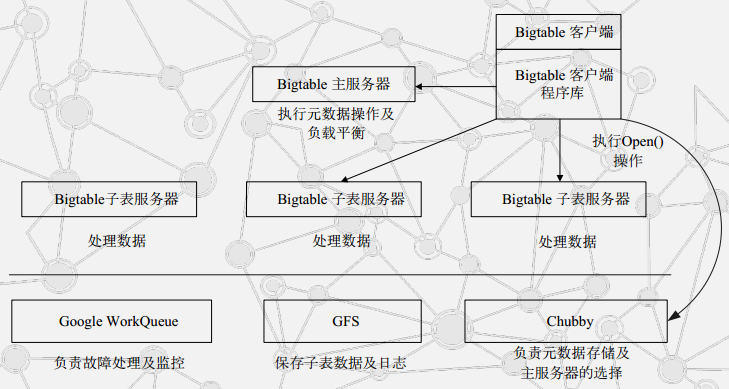
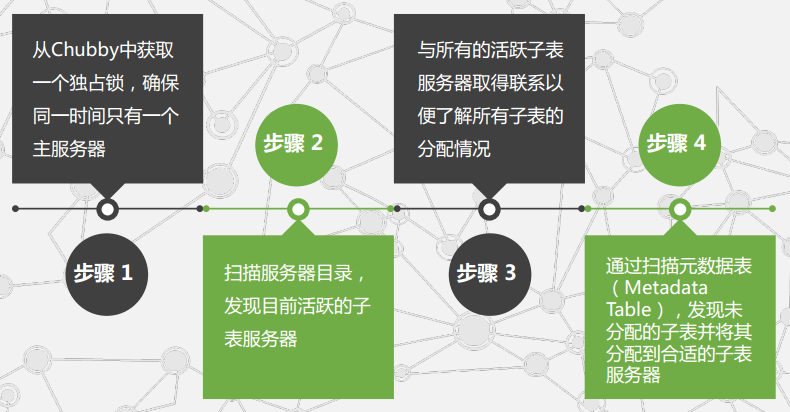
其中Cubby的作用:选 取 并 保 证 同 一 时 间 内 只 有 一 个 主 服 务 器(M a s t e r S e r v e r ) 。获 取 子 表 的 位 置 信 息.保 存 B i g t a b l e 的 模 式 信 息 及 访 问 控 制 列 表 。
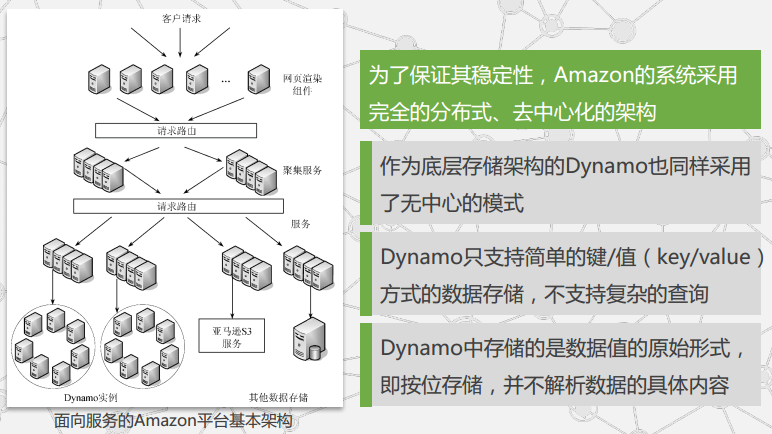
AWS技术
Dynamo技术架构
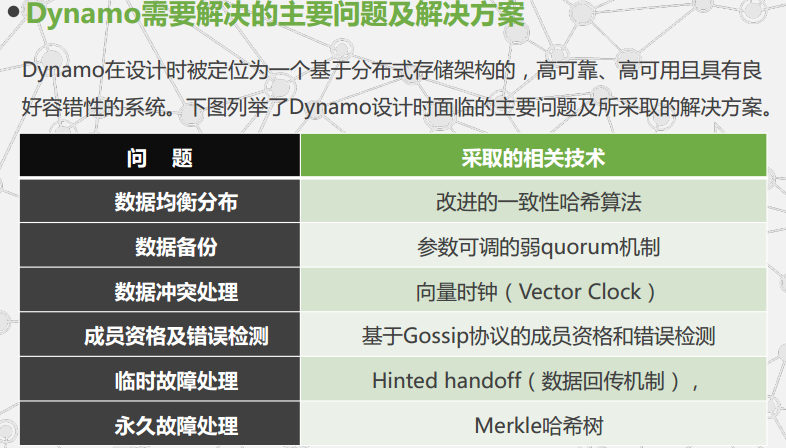
一致性hash: Dynamo中引入了虚拟节点的概念每个虚拟节点都隶属于某一个实际的物理节点,一个物理节点根据其性能的差异被分为一个或多个虚拟节点。各个虚拟节点的能力基本相当,并随机分布在哈希环上
解决数据冲突:Dynamo中采用了向量时钟技术,用[node,cunter]对来表示,Node是操作节点,counter是对应的计数器,初始值为0,每进行一次更新操作都计数器加一;
容错机制:
- 临时故障处理:Dynamo中采用了一种带有监听的数据回传机制(Hinted Handoff)当虚拟节点A失效后,会将数据临时存放在节点D的临时空间中,并在节点A重新可用后,由节点D将数据回传给节点A
- 永久性故障处理机制:采用Merkle哈希树技术来加快检测和减少数据传输量
s3服务
简单存储服务(Simple Storage Services,S3)构架在Dynamo之上,用于提供任意类型文件的临时或永久性存储。 S3的总体设计目标是可靠、 易用及低成本。
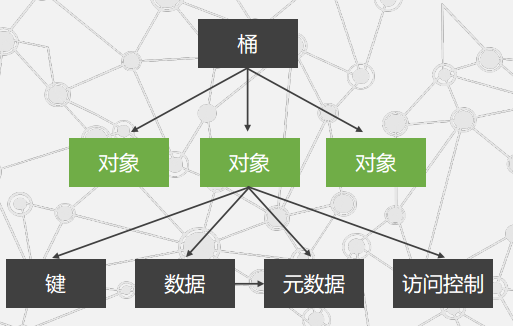
- 桶是用于存储对象的容器,其作用类似于文件夹,但桶不可以被嵌套,即在桶中不能创建桶
- 对象:包含数据(任意类型,但大小收到对象的最大容量限制)和元数据(数据的附加描述信息,通过name-value的形式定义);
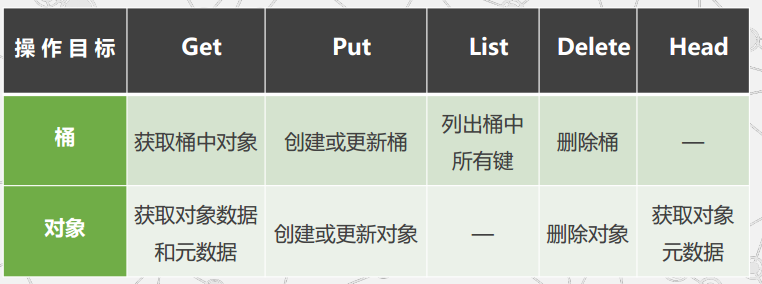
S3中采用了最终一致性模型。
用户操作 | 结果
1 写入一个新的对象并立即读取它 服务器可能返回“键不存在”
2 写入一个新的对象并立即列出桶中已有的对象 该对象可能不会出现在列表中
3 用新数据替换现有的对象并立即读取它 服务器可能返回原有的数据
4 删除现有的对象并立即读取它 服务器可能返回被删除的数据
5 删除现有的对象并立即列出桶中的所有对象 服务器可能列出被删除的对象
s3的安全措施:加密Hash函数;共享密钥的消息认证协议;s3的acl不具有继承性
非关系型数据库simpleDB和DynamoDB


simpleDB:域(用于存放一定关联关系的数据的容器),条目(对于一个记录,通过属性来描述,是属性的集合),属性(是条目的特征,用对与条目的某个方面进行概括性描述,每个条目有多个属性)值(描述属性的具体内容)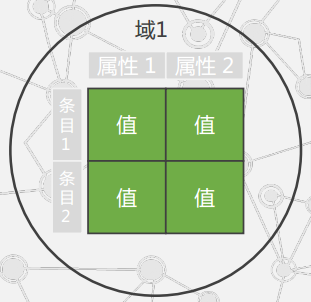
DynamoDB:以表为基本单位,条目不用预先定义,取消了对表中数据的大小的限制,用户设置任意大小,并自动分配到多个服务器上面;不再固定使用最终一致性模型,允许用户选择弱一致或强一致,

RDS
用mysql的

微软的云计算平台

windows azure云操作系统
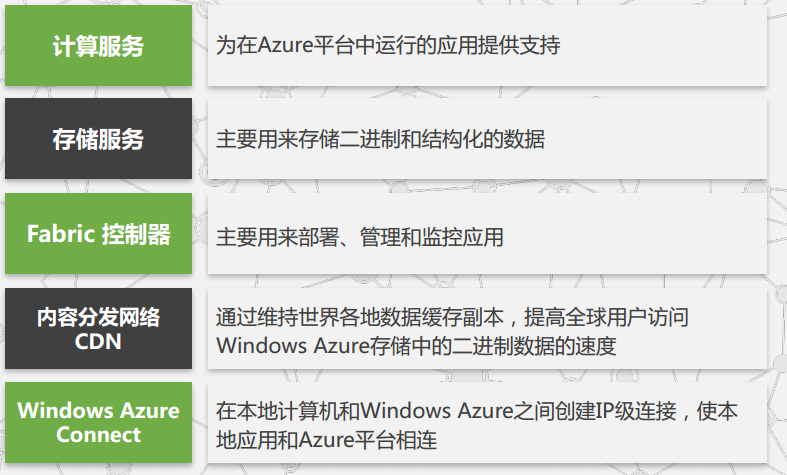
Windows Azure是一个服务平台,用户利用该平台,通过互联网访问微软数据中心运行Windows应用程序和存储应用程序数据,这些应用程序可以向用户提供服务;提供了托管的、 可扩展的、 按需应用的计算和存储资源,同时还提供了云平台管理和动态分配资源的控制手段
发表回复