[TOC]
简介
是一个分布式调用框架,高可用的调度服务,在hadoop中担任任务分配和调度的工作;提供java和c的接口.本文中在java中进行使用
安装与配置
在java环境中运行,因此要安装java的jdk,在linux中使用java -version查看版本;
从网上下载zookeeper的源文件,是个压缩包,解压后使用
在conf文件夹下创建配置文件 cd ./conf vim zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/opt/zookeeper-data/
clientPort=2181
- 参数介绍
tickTime:指定了ZooKeeper的基本时间单位(以毫秒为单位);
initLimit:指定了启动zookeeper时,zookeeper实例中的随从实例同步到领导实例的初始化连接时间限制,超出时间限制则连接失败(以tickTime为时间单位);
syncLimit:指定了zookeeper正常运行时,主从节点之间同步数据的时间限制,若超过这个时间限制,那么随从实例将会被丢弃;
dataDir:zookeeper存放数据的目录;
clientPort:用于连接客户端的端口。
然后在./bin中 打开./zkServer.sh start 服务器端, ./zkCli.sh start客户端的; 使用status 查看状态
原理介绍
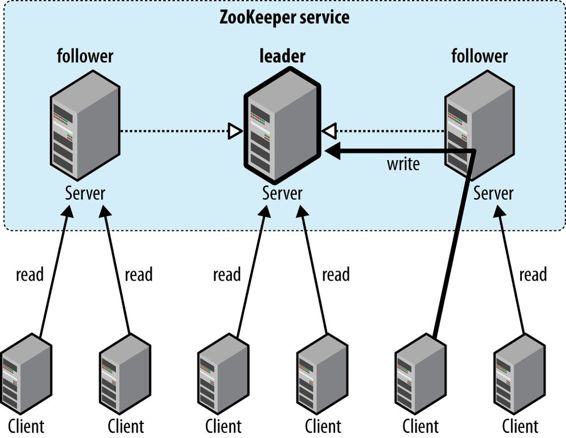
有一个leader 和若干个client和server(leader在server中 ,有一个leader的选举算法——–).
数据模型
- zookeeper是一个树形结构的数据模型–znode. 一个znode包含了存储数据和ACL,设计成使用于存储少量的数据,因此znode的存储是不超过1M的
- 数据访问时原子性的,使用path进行定位,/zoo/node1/…等
- znode的序号:当创建一个znode,指定命名/a/b-,那么zook会为我们创建一个/a/b-3的znode,再次请求创建一个/a/b-时就会创建一个/a/b-5的序号不断增长,来确定不同的版本,用于排序
- znode类型:分为两种 短暂和持久的. znode的类型在创建时已经确定且之后就无法更改,短暂znode在客户端会话结束后就会被删除,因此无法有子节点.
APIs
操作主要有
- create:创建一个znode必须要有父节点
- delect:删除,不能有子节点:提供序号
- exists:测试znode是否存在并查询其元数据:要提供序号
- getACL,setACL:获取/设置znode的ACL
- getChildren:获取子节点列表
- getData,setData:获得znode保存的数据
- sync:将客户端的znode视图和zookeeper同步
java和c的接口都有
分为同步api和异步的api
同步的方式public Stat exists(String path, Watcher watcher) throws KeeperException,InterruptedException
异步的public void exists(String path, Watcher watcher, StatCallback cb, Object ctx)
异步返回值都是void.自行选择使用同步还是异步的.
- 观察触发器:在进行读操作 exit getChildren,getData时,可以设置观察,
ACLs 访问控制
当znode创建时,会给它一个ACLs 来决定谁可以对znode做哪些操作.
zookeeper通过鉴权来获取客户端的身份,通过ACL来控制客户端的访问.digest(使用用户名和密码),sasl(使用Kerberos),ip(使用客户端ip进行鉴权)
exits操作不受ACL的限制,
实现
zookeeper服务有两种模式,一种是独立模式(standalone 只用一个服务器,用于测试),另外一个是复制模式运行于一个计算机集群上,称其为”集合体”,zoo通过复制实现高可用性.只要集合体中半数以上的服务器可以使用,就能提供服务.大于n/2;
1. 领导者选举:一台领导者,其他都是跟随者,当半数以上的跟随者已经将其状态和领导者同步,此过程完成;
2. 原子广播:所有的写请求已经转发给领导者,再由领导者更新广播给跟随者.当半数以上的跟随者持久化这个写操作后,领导者才会提交这个更新,客户端会收到更新成功的响应.(设计成原子性)
3. 领导者故障:重新选取一个领导者,恢复后成为跟随者.
一致性
顺序一致:某个客户端的提交会被顺序执行
原子性:要么更新成功,要么失败
单一系统映像:客户端无论连接到哪台服务器,看起来都是相同的系统视图
持久化:更新一旦被提交,就不会被更改操作.
会话
每个客户端都会保存集合体中服务器的列表,客户端启动时会尝试连接列表中的一台服务器.连接成功,这台服务器就会为该客户端创建一个新的会话(有超时限制,要发送心跳包保持会话).客户端可以进行故障切换.所有的会话还是有效的.
时间: “滴答”(tick time)参数定义了基本的时间周期(其他都是根据此为单位的).会话的超时范围为2–20个滴答,短的超时时间会使故障检测响应变短
状态转换
图
构建应用
- 配置服务:
可复原的应用
在javaAPI中的每一个zookeeper都声明了两种类型的异常InterruptException和KeeperException.
InterruptException:如果操作被中断就会有一个Inter异常被抛出,但它并不意味着有故障,而是表明响应的操作已经被取消(java的线程也会抛出中断异常)
KeeperExce: 如果zookeeper服务器发出一个错误信号或者与服务器存在通信异常,则抛出keeper异常,keeper异常有不少子类,例如:NONodeException(当试图针对不存在的znode进行操作时 null异常),
– 分为三大类
– 状态异常 :当一个操作不能应用于znode树时导致失败
– 可恢复异常 :应用程序能够在同一个zook会话中恢复的异常(例如会话丢失后重连,换服务器等,)
– 不可恢复异常:zookeeper的会话会失效,超时或者被动关闭或身份验证失败等
锁服务
分布式锁在一组进程中提供了一种互斥机制,在任何时刻,只有一个进程可以持有锁.分布式锁可以用于在大型分布式系统中实现领导者选举,在任何时间点,持有锁的那个进程就是系统的领导者
使用zookeepre实现分布式锁:使用顺序znode来为那些竞争锁的进行进行强制排序,首先先指定一个作为锁的znode,用它来描述被锁定的实体,称为/leader;然后希望获得锁的客户端创建一些短暂顺序的znode,作为锁znode的子节点.在任何时间点,顺序号最小的客户端将持有锁;
过程如下:
- 在锁znode下创建名为lock-的短暂顺序znode,并且记录它的实际路径名;
- 查询锁的znode的子节点并且设置一个观察;
- 如果步骤1所创建的znode在步骤2中所返回的所有子节点中具有最小序列号,则获得锁,并退出;
- 等待步骤2中设置的观察的通知并转移到步骤2;
羊群效应:考虑到有成百上千的客户端,所有客户端都尝试获得锁,每个都在znode上设置一个watcher,每次锁的释放或者申请锁,观察都会被触发并且每个设观察的客户端都会获得通知(很僵硬);实际上只有一小部分需要处理这个事件.但是这种操作会产生峰值流量;
发表回复