部署安装
docker network create flink-network
docker run -itd –name=jobmanager –publish 8091:8081 –network flink-network –env FLINK_PROPERTIES="jobmanager.rpc.address: jobmanager" flink jobmanager
docker run -itd –name=taskmanger –network flink-network –env FLINK_PROPERTIES="jobmanager.rpc.address: jobmanager" flink taskmanager
FLINK_PROPERTIES="jobmanager.rpc.address: jobmanager"
docker run \
-itd \
--name=jobmanager \
--network flink-network \
--publish 8081:8081 \
--env FLINK_PROPERTIES="${FLINK_PROPERTIES}" \
flink:1.18.1-scala_2.12 jobmanagerdocker run \
-itd \
--name=taskmanager \
--network flink-network \
--env FLINK_PROPERTIES="${FLINK_PROPERTIES}" \
flink:1.18.1-scala_2.12 taskmanagerflink 使用场景
大数据场景下,从一个数据源到另一个数据源
• 数据清洗,有字段为null,数据错误
• 数据多表关联聚合为宽表
• 数据聚合,日活,月活
• 数据过滤,在无休止的数据流中找到需要的数据或者事件
流批一体: 数据既可以当流一直计算,也可以当成批计算一批数据
连接器: 提供了高效的kafka连接器,jdbc,es等连接器,开箱即用,用来做数据读取输入,和数据输出
// kafka 连接器,消费kafka数据,转成 dataStream
SimpleStringSchema simpleStringSchema = new org.apache.flink.api.common.serialization.SimpleStringSchema();
KafkaSource<String> kafkaSource = KafkaSource.<String>builder().setBootstrapServers(bootStrap).setGroupId(groupId).setTopics(topic)
//.setProperty("sasl.jaas.config","org.apache.kafka.common.security.plain.PlainLoginModule required username='your_username' password='your_password';")
.setProperty("max.poll.records", "500").setProperty("retry.backoff.ms", "1000").setProperty("retries", "5").setProperty("reconnect.backoff.max.ms", "10000")
.setStartingOffsets(OffsetsInitializer.timestamp(Long.parseLong(startKafkaOffsetTimestamp)))
.setValueOnlyDeserializer(simpleStringSchema).build();
DataStreamSource<String> dataStream = env.fromSource(kafkaSource, WatermarkStrategy.forMonotonousTimestamps(), "kafka source");
分区:根据key将数据分成独立的流(每个key一个流),某个流的数据,可以进行调用,类似kafka 的分区,
.keyBy(DBLogUsage::getId)
窗口: 按照时间来将数据流划分成一个一个的桶,然后交给后面的窗口函数进行计算
.window(TumblingProcessingTimeWindows.of(Time.seconds(30)))
水印: 划分窗口时用的时间,有些时间是根据业务后面添加的,要主动告诉窗口当前数据流里面的每一条数据的水印是啥,才能划分到不同的窗口
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<Event>(Time.seconds(1)) {
@Override
public long extractTimestamp(Event event) {
return event.timestamp;
}
})窗口函数:数据被拆成不同的窗口后,进行计算的逻辑
// 实现聚合操作的
.process(new ProcessWindowFunction<Event, Object, String, TimeWindow>() {
@Override
public void process(String s, ProcessWindowFunction<Event, Object, String, TimeWindow>.Context context, Iterable<Event> iterable, Collector<Object> collector) throws Exception {
long sum = 0;
for (Event e : iterable) {
sum++;
}
collector.collect(new Tuple2<>(s, sum));
}
})数据统计的发展
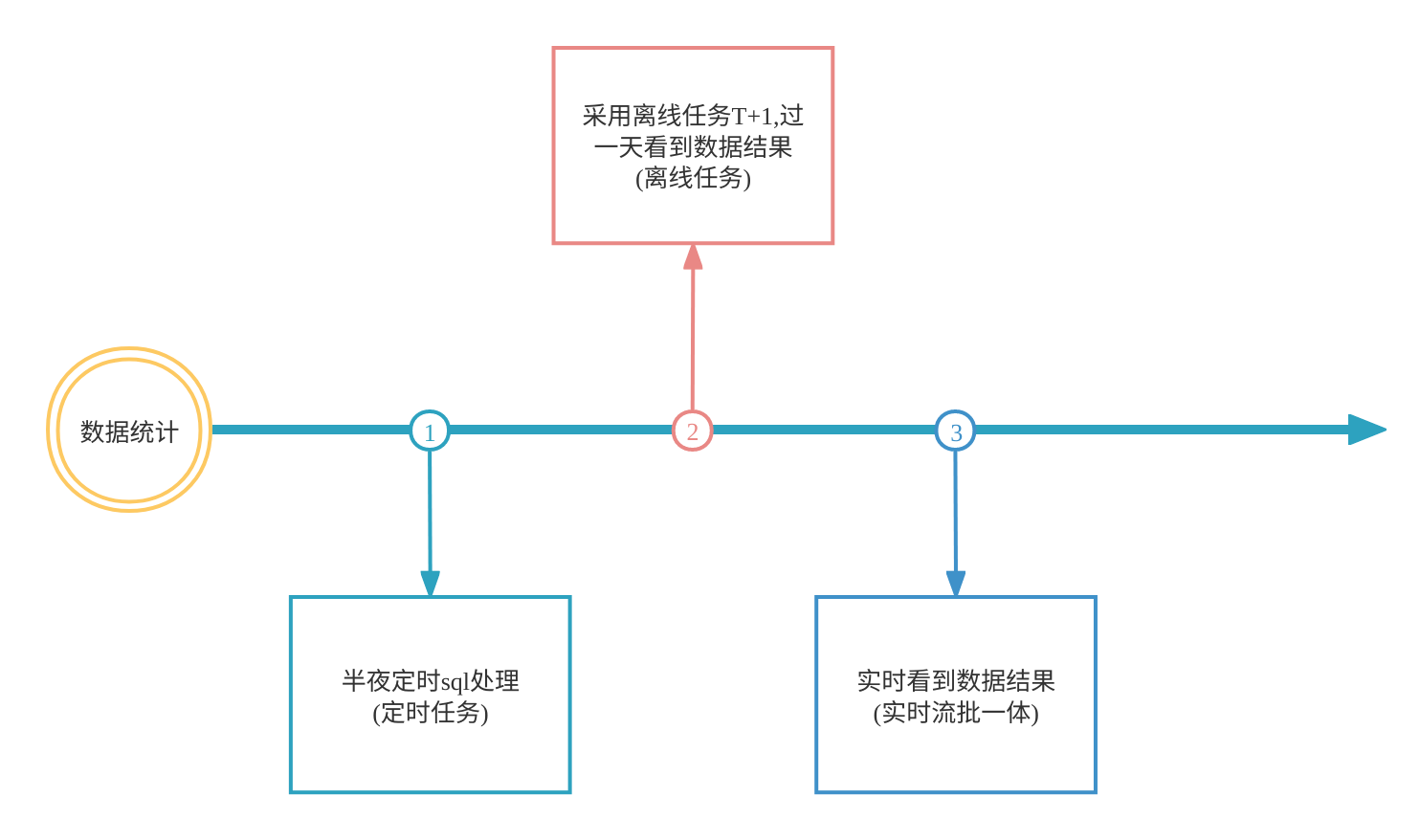
在阶段1:每天启动定时任务,从mysql中分批读取数据,在java 代码中来进行数据统计
• 业务复杂,每次定时任务要自己写很多聚合逻辑,还要自己处理mysql连接异常,读取异常
• 没有有效的可靠性机制,定时任务失败没有重试,如果失败,只能后续补数据.
• 依赖sql 优化,因为是基于mysql 做查询,如果查某一天的日活数据,因为超时查询失败就会一直失败
在阶段2: 引入了flink 框架,实现了读取数据库里面的数据,然后分批进行数据流运算,启用了一个时间为一天的窗口
在阶段3: 日活数据能实时看到,比如现在9点能看到 0点到9点当前的日活结果
根据上面的flink 代码如何实现第二阶段批处理和第三阶段的实时流
其实第二阶段很好实现就是使用窗口函数.window(TumblingEventTimeWindows.of(Time.days(1))) 设置一个滚动一天的窗口,等一天后执行窗口函数process等进行聚合,但是问题来了,这种批处理要等一天,不能实时看到一天内的日活.数据存在flink里面一天过去后才进行处理
如何能够使用flink 且能看到一天内的实时的日活呢
其实代码使用的不变,流程变了一点
如下步骤:
- 先根据时间进行keyBy,分流,将比如0729的日活数据分流
2.在process 里面使用MapState进行userId 去重,然后使用ValueState 对当前日活数据进行加一操作, - 在第二步输出的内容不再是日活最终数据了,而是日活valuseState 的值, 比如 六条日活数据,输出1,2,3,4,5,6
- 在第三步输出的dataSteam流中(1,2,3,4,5,6) 再起一个一秒的窗口,获取流里面最大的值6,然后进行sink 输出到数据库等中
这样就可以做到去重及准实时获取日活数据
发表回复